





brain of mat kelcey...
mongodb + twitter + yahoo term extractor = fun!
March 07, 2010 at 09:38 PM | categories: Uncategorized
ran a little experiment in using yahoo term extraction yesterday and it worked well enough. here's some code to pass some text to yahoo and get back an array of termsi've got to say mongodb is such an easy tool...
what to do with a week off?
February 22, 2010 at 06:42 PM | categories: Uncategorized
this week i'm between jobs so i have (a little) more time than usual to hack.i've got a list of pending things to do but can't decide what to do next, here's my list in (sort of) priority order...fix up...
semi supervised naive bayes for text classification
February 14, 2010 at 09:46 PM | categories: Uncategorized
experiment 13; a test of semi supervised naive bayes for text classification is complete.semi supervised algorithms seem to work pretty well and i can see how they are a huge benefit for text classification where you can have an enormous...
e12.3 stat syns FAIL!
February 05, 2010 at 08:31 PM | categories: Uncategorized
after quite a bit of hacking the statistical synonyms idea doesn't seem to give terribly interesting results so i'm going onto do something else.for the record here's what I did do though....generate 3grams from 800e3 tweetscollect n-grams together that share...
an intro to semi supervised document classification
January 31, 2010 at 02:02 PM | categories: Uncategorized
here's a great lecture from tom mitchell about document classification using a semi supervised version of naive bayes.semi supervised algorithms only require some of the training examples to be labeled and are able to make use of any unlabelled ones,...
e12.2 entity set expansion
January 28, 2010 at 08:18 PM | categories: Uncategorized
i've been doing some reading for my statistical synonyms project and have uncovered a heap of cool papers. most of them are around an idea (from the 1950's!) called the distributional hypothesis that simply states that words that appear in...
e12.1 statistical synonyms
January 23, 2010 at 12:54 PM | categories: Uncategorized
i've had an idea brewing in my head for awhile now seeded by a great talk by peter norvig about statistically approaches to find patterns in data.one thing he alludes to is the generation of synoyms based on n-gram models.the...
a pig screencast
January 17, 2010 at 02:22 PM | categories: Uncategorized
pig demo from Mat Kelcey on Vimeo.based on a talk i gave at work recently...
tweets about cheese
November 15, 2009 at 08:45 PM | categories: Uncategorized
people tweet about all sorts of stuff.sometimes it's really important ground breaking world changing stuff...but most of the time it's ridiculous waste of time stuff like 'i ate some cheese'in fact how much do people actually tweet about cheese?and when...
xargs parallel execution
November 06, 2009 at 09:57 PM | categories: Uncategorized
just recently discovered xargs has a parallelise option!i have 20 files, sample.01.gz to sample.20.gz, each ~100mb in size that i need to run a script overone option iszcat sample*gz | ./script.rb > outputbut this will process the files sequentially on...
e11.3 at what time does the world tweet?
October 28, 2009 at 09:22 PM | categories: Uncategorized
consider the graph below which shows the proportion of tweets per 10 min slot of the day (GMT0)it compares 4.7e6 tweets with any location vs 320e3 tweets with identifiable lat lonssome interesting observations with unanswered questions...the ebb and flow is...
e11.2 aggregating tweets by time of day
October 24, 2009 at 01:02 PM | categories: Uncategorized
for v3 lets aggregate by time of the day, should make for an interesting animationbrowsing the data there are lots of other lat longs in data, not just iPhone: and ÜT: there are also one tagged with Coppó:, Pre:, etc...
e11.1 from bash scripts to hadoop
October 18, 2009 at 02:10 PM | categories: Uncategorized
let's rewrite v1 using hadoop tooling, code is on githubwe'll run hadoop in non distributed standalone mode. in this mode everything runs in a single jvm so it's nice and simple to dev against.in v1 it wasbzcat sample.bz2 | ./extract_locations.pl...
e11.0 tweets around the world
October 16, 2009 at 08:47 PM | categories: Uncategorized
was discussing the streaming twitter api with steve and though i knew about the private firehose i didn't know there was a lighter weight public gardenhose interface!since discovering this my pvr has basically been runningcurl -u mat_kelcey:XXX http://stream.twitter.com/1/statuses/sample.json |\ ...
e10.4 communities in social graphs
October 06, 2009 at 08:05 PM | categories: Uncategorized
social graphs, like twitter or facebook, often follow the pattern of having clusters of highly connected components with an occasional edge joining these clusters.these connecting edges define the boundaries of communities in the social network and can be identified by...
simple statistics with R
October 03, 2009 at 03:43 PM | categories: Uncategorized
i'm learning a new statistics language called R and it's pretty cool.make a vector ...12> c(3,1,4,1,5,9,2,6,5,3,5,8) [1] 3 1 4 1 5 9 2 6 5 3 5 8turn it into a frequency table ...123> table(c(3,1,4,1,5,9,2,6,5,3,5,8))1 2 3 4 5...
do a degree via youtube
October 01, 2009 at 08:40 PM | categories: Uncategorized
i'm amazed by how much great content is on youtube, how could you NOT learn something!?13 x 1hr Statistical Aspects of Data Mining (Stats 202)20 x 1hr Machine Learning...
e10.3 twitter crawl progress
September 29, 2009 at 08:43 PM | categories: Uncategorized
since the twitter api is rate limited it's quite slow to crawl twitter and after a most of a week i've still only managed to get info on 8,000 users. i probably should subscribe to get a 20,000 an hr...
e10.2 tgraph crawl order example
September 21, 2009 at 09:58 PM | categories: Uncategorized
let's consider an example of the crawl order for tgraph...we seed our frontier with 'a' and bootstrap cost of 0.fetching the info for 'a' shows 2 outedges to 'b' and 'c', from our cost formula these all have cost 0...
e10.1 crawling twitter
September 19, 2009 at 09:31 PM | categories: Uncategorized
our first goal is to get some data and the twitter api makes getting the data trivial. i'm focused mainly on the friends stuff but because it only gives user ids i'll also get the user info so i can...
« Previous Page -- Next Page »
popular posts...
FPGA wavenets : eurorack audio processing neural nets running at ~200,000 inferences/sec (oct 2023)

dithernet very slow movie player : a GAN that slowly plays a movie over a year on an eink screen (oct 2020)

evolved channel selection : neural networks robust to any subset of input channels, at any resolution (mar 2021)

ensemble nets : training ensembles as a single model using jax on a tpu pod slice (sept 2020)
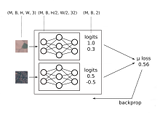
bnn : counting bees with a rasp pi (may 2018)

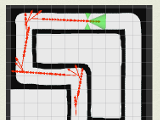
drivebot : learning to do laps with reinforcement learning and neural nets (feb 2016)
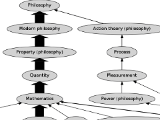
wikipedia philosophy : do all first links on wikipedia lead to philosophy? (aug 2011)
some papers from my time at google research / brain...
- Natural Questions: a Benchmark for Question Answering Research
- Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping
- WikiReading: A Novel Large-scale Language Understanding Task over Wikipedia
my honours thesis
the co-evolution of cooperative behaviour (1997) evolving neural nets with genetic algorithms for communication problems.
old projects...
- latent semantic analysis via the singular value decomposition (for dummies)
- semi supervised naive bayes
- statistical synonyms
- round the world tweets
- decomposing social graphs on twitter
- do it yourself statistically improbable phrases
- should i burn it?
- the median of a trillion numbers
- deduping with resemblance metrics
- simple supervised learning / should i read it?
- audioscrobbler experiments
- chaoscope experiment